|
crocoddyl
1.9.0
Contact RObot COntrol by Differential DYnamic programming Library (Crocoddyl)
|


|
|
crocoddyl
1.9.0
Contact RObot COntrol by Differential DYnamic programming Library (Crocoddyl)
|
|
Differential Dynamic Programming (DDP) solver. More...
#include <crocoddyl/core/solvers/ddp.hpp>
Public Member Functions | |
| SolverDDP (boost::shared_ptr< ShootingProblem > problem) | |
| Initialize the DDP solver. More... | |
| virtual void | allocateData () |
| Allocate all the internal data needed for the solver. | |
| virtual void | backwardPass () |
| Run the backward pass (Riccati sweep) More... | |
| virtual double | calcDiff () |
| Update the Jacobian, Hessian and feasibility of the optimal control problem. More... | |
| virtual void | computeDirection (const bool recalc=true) |
| Compute the search direction \((\delta\mathbf{x}^k,\delta\mathbf{u}^k)\) for the current guess \((\mathbf{x}^k_s,\mathbf{u}^k_s)\). More... | |
| virtual void | computeGains (const std::size_t t) |
| Compute the feedforward and feedback terms using a Cholesky decomposition. More... | |
| void | decreaseRegularization () |
Decrease the state and control regularization values by a regfactor_ factor. | |
| DEPRECATED ("Use get_reg_incfactor() or get_reg_decfactor()", double get_regfactor() const ;) double get_reg_min() const | |
| Return the regularization factor used to decrease / increase it. More... | |
| DEPRECATED ("Use get_reg_max()", double get_regmax() const) | |
| DEPRECATED ("Use get_reg_min()", double get_regmin() const) | |
| DEPRECATED ("Use set_reg_incfactor() or set_reg_decfactor()", void set_regfactor(const double reg_factor);) void set_reg_min(const double regmin) | |
| Modify the regularization factor used to decrease / increase it. More... | |
| DEPRECATED ("Use set_reg_max()", void set_regmax(const double regmax)) | |
| DEPRECATED ("Use set_reg_min()", void set_regmin(const double regmin)) | |
| virtual const Eigen::Vector2d & | expectedImprovement () |
| Return the expected improvement \(dV_{exp}\) from a given current search direction \((\delta\mathbf{x}^k,\delta\mathbf{u}^k)\). More... | |
| virtual void | forwardPass (const double stepLength) |
| Run the forward pass or rollout. More... | |
| const std::vector< double > & | get_alphas () const |
| Return the set of step lengths using by the line-search procedure. | |
| const std::vector< MatrixXdRowMajor > & | get_K () const |
| Return the feedback gains \(\mathbf{K}_{s}\). | |
| const std::vector< Eigen::VectorXd > & | get_k () const |
| Return the feedforward gains \(\mathbf{k}_{s}\). | |
| const std::vector< Eigen::VectorXd > & | get_Qu () const |
| Return the Jacobian of the Hamiltonian function \(\mathbf{Q}_{\mathbf{u}_s}\). | |
| const std::vector< Eigen::MatrixXd > & | get_Quu () const |
| Return the Hessian of the Hamiltonian function \(\mathbf{Q}_{\mathbf{uu}_s}\). | |
| const std::vector< Eigen::VectorXd > & | get_Qx () const |
| Return the Jacobian of the Hamiltonian function \(\mathbf{Q}_{\mathbf{x}_s}\). | |
| const std::vector< Eigen::MatrixXd > & | get_Qxu () const |
| Return the Hessian of the Hamiltonian function \(\mathbf{Q}_{\mathbf{xu}_s}\). | |
| const std::vector< Eigen::MatrixXd > & | get_Qxx () const |
| Return the Hessian of the Hamiltonian function \(\mathbf{Q}_{\mathbf{xx}_s}\). | |
| double | get_reg_decfactor () const |
| Return the regularization factor used to decrease the damping value. | |
| double | get_reg_incfactor () const |
| Return the regularization factor used to increase the damping value. | |
| double | get_reg_max () const |
| Return the maximum regularization value. | |
| double | get_th_grad () const |
| Return the tolerance of the expected gradient used for testing the step. | |
| double | get_th_stepdec () const |
| Return the step-length threshold used to decrease regularization. | |
| double | get_th_stepinc () const |
| Return the step-length threshold used to increase regularization. | |
| const std::vector< Eigen::VectorXd > & | get_Vx () const |
| Return the Hessian of the Value function \(V_{\mathbf{x}_s}\). | |
| const std::vector< Eigen::MatrixXd > & | get_Vxx () const |
| Return the Hessian of the Value function \(V_{\mathbf{xx}_s}\). | |
| void | increaseRegularization () |
Increase the state and control regularization values by a regfactor_ factor. | |
| virtual void | resizeData () |
| Resizing the solver data. More... | |
| void | set_alphas (const std::vector< double > &alphas) |
| Modify the set of step lengths using by the line-search procedure. | |
| void | set_reg_decfactor (const double reg_factor) |
| Modify the regularization factor used to decrease the damping value. | |
| void | set_reg_incfactor (const double reg_factor) |
| Modify the regularization factor used to increase the damping value. | |
| void | set_reg_max (const double regmax) |
| Modify the maximum regularization value. | |
| void | set_th_grad (const double th_grad) |
| Modify the tolerance of the expected gradient used for testing the step. | |
| void | set_th_stepdec (const double th_step) |
| Modify the step-length threshold used to decrease regularization. | |
| void | set_th_stepinc (const double th_step) |
| Modify the step-length threshold used to increase regularization. | |
| virtual bool | solve (const std::vector< Eigen::VectorXd > &init_xs=DEFAULT_VECTOR, const std::vector< Eigen::VectorXd > &init_us=DEFAULT_VECTOR, const std::size_t maxiter=100, const bool is_feasible=false, const double init_reg=1e-9) |
| Compute the optimal trajectory \(\mathbf{x}^*_s,\mathbf{u}^*_s\) as lists of \(T+1\) and \(T\) terms. More... | |
| virtual double | stoppingCriteria () |
| Return a positive value that quantifies the algorithm termination. More... | |
| virtual double | tryStep (const double steplength=1) |
| Try a predefined step length \(\alpha\) and compute its cost improvement \(dV\). More... | |
 Public Member Functions inherited from SolverAbstract Public Member Functions inherited from SolverAbstract | |
| EIGEN_MAKE_ALIGNED_OPERATOR_NEW | SolverAbstract (boost::shared_ptr< ShootingProblem > problem) |
| Initialize the solver. More... | |
| double | computeDynamicFeasibility () |
| Compute the dynamic feasibility \(\|\mathbf{f}_{\mathbf{s}}\|_{\infty,1}\) for the current guess \((\mathbf{x}^k,\mathbf{u}^k)\). More... | |
| double | get_cost () const |
| Return the total cost. | |
| const Eigen::Vector2d & | get_d () const |
| Return the LQ approximation of the expected improvement. | |
| double | get_dV () const |
| Return the cost reduction \(dV\). | |
| double | get_dVexp () const |
| Return the expected cost reduction \(dV_{exp}\). | |
| double | get_ffeas () const |
| Return the feasibility of the dynamic constraints \(\|\mathbf{f}_{\mathbf{s}}\|_{\infty,1}\) of the current guess. | |
| const std::vector< Eigen::VectorXd > & | get_fs () const |
| Return the gaps \(\mathbf{f}_{s}\). | |
| bool | get_inffeas () const |
| Return the norm used for the computing the feasibility (true for \(\ell_\infty\), false for \(\ell_1\)) | |
| bool | get_is_feasible () const |
| Return the feasibility status of the \((\mathbf{x}_s,\mathbf{u}_s)\) trajectory. | |
| std::size_t | get_iter () const |
| Return the number of iterations performed by the solver. | |
| const boost::shared_ptr< ShootingProblem > & | get_problem () const |
| Return the shooting problem. | |
| double | get_steplength () const |
| Return the step length \(\alpha\). | |
| double | get_stop () const |
Return the value computed by stoppingCriteria() | |
| double | get_th_acceptstep () const |
| Return the threshold used for accepting a step. | |
| double | get_th_gaptol () const |
| Return the threshold for accepting a gap as non-zero. | |
| double | get_th_stop () const |
| Return the tolerance for stopping the algorithm. | |
| double | get_ureg () const |
| Return the control regularization value. | |
| const std::vector< Eigen::VectorXd > & | get_us () const |
| Return the control trajectory \(\mathbf{u}_s\). | |
| double | get_xreg () const |
| Return the state regularization value. | |
| const std::vector< Eigen::VectorXd > & | get_xs () const |
| Return the state trajectory \(\mathbf{x}_s\). | |
| const std::vector< boost::shared_ptr< CallbackAbstract > > & | getCallbacks () const |
| Return the list of callback functions using for diagnostic. | |
| void | set_inffeas (const bool inffeas) |
| Modify the current norm used for computed the feasibility. | |
| void | set_th_acceptstep (const double th_acceptstep) |
| Modify the threshold used for accepting step. | |
| void | set_th_gaptol (const double th_gaptol) |
| Modify the threshold for accepting a gap as non-zero. | |
| void | set_th_stop (const double th_stop) |
| Modify the tolerance for stopping the algorithm. | |
| void | set_ureg (const double ureg) |
| Modify the control regularization value. | |
| void | set_us (const std::vector< Eigen::VectorXd > &us) |
| Modify the control trajectory \(\mathbf{u}_s\). | |
| void | set_xreg (const double xreg) |
| Modify the state regularization value. | |
| void | set_xs (const std::vector< Eigen::VectorXd > &xs) |
| Modify the state trajectory \(\mathbf{x}_s\). | |
| void | setCallbacks (const std::vector< boost::shared_ptr< CallbackAbstract > > &callbacks) |
| Set a list of callback functions using for the solver diagnostic. More... | |
| void | setCandidate (const std::vector< Eigen::VectorXd > &xs_warm=DEFAULT_VECTOR, const std::vector< Eigen::VectorXd > &us_warm=DEFAULT_VECTOR, const bool is_feasible=false) |
| Set the solver candidate trajectories \((\mathbf{x}_s,\mathbf{u}_s)\). More... | |
Public Attributes | |
| EIGEN_MAKE_ALIGNED_OPERATOR_NEW typedef MathBaseTpl< double >::MatrixXsRowMajor | MatrixXdRowMajor |
Protected Attributes | |
| std::vector< double > | alphas_ |
| Set of step lengths using by the line-search procedure. | |
| double | cost_try_ |
| Total cost computed by line-search procedure. | |
| std::vector< Eigen::VectorXd > | dx_ |
| State error during the roll-out/forward-pass (size T) | |
| Eigen::VectorXd | fTVxx_p_ |
| Store the value of \(\mathbf{\bar{f}}^T\mathbf{V_{xx}}^{'}\). | |
| std::vector< MatrixXdRowMajor > | FuTVxx_p_ |
| Store the values of \(\mathbf{f_u}^T\mathbf{V_{xx}}^{'}\) per each running node. | |
| MatrixXdRowMajor | FxTVxx_p_ |
| Store the value of \(\mathbf{f_x}^T\mathbf{V_{xx}}^{'}\). | |
| std::vector< MatrixXdRowMajor > | K_ |
| Feedback gains \(\mathbf{K}\). | |
| std::vector< Eigen::VectorXd > | k_ |
| Feed-forward terms \(\mathbf{l}\). | |
| std::vector< Eigen::VectorXd > | Qu_ |
| Gradient of the Hamiltonian \(\mathbf{Q_u}\). | |
| std::vector< Eigen::MatrixXd > | Quu_ |
| Hessian of the Hamiltonian \(\mathbf{Q_{uu}}\). | |
| std::vector< Eigen::LLT< Eigen::MatrixXd > > | Quu_llt_ |
| Cholesky LLT solver. | |
| std::vector< Eigen::VectorXd > | Quuk_ |
| Store the values of. | |
| std::vector< Eigen::VectorXd > | Qx_ |
| Gradient of the Hamiltonian \(\mathbf{Q_x}\). | |
| std::vector< Eigen::MatrixXd > | Qxu_ |
| Hessian of the Hamiltonian \(\mathbf{Q_{xu}}\). | |
| std::vector< Eigen::MatrixXd > | Qxx_ |
| Hessian of the Hamiltonian \(\mathbf{Q_{xx}}\). | |
| double | reg_decfactor_ |
| Regularization factor used to decrease the damping value. | |
| double | reg_incfactor_ |
| Regularization factor used to increase the damping value. | |
| double | reg_max_ |
| Maximum allowed regularization value. | |
| double | reg_min_ |
| Minimum allowed regularization value. | |
| double | th_grad_ |
| Tolerance of the expected gradient used for testing the step. | |
| double | th_stepdec_ |
| Step-length threshold used to decrease regularization. | |
| double | th_stepinc_ |
| Step-length threshold used to increase regularization. | |
| std::vector< Eigen::VectorXd > | us_try_ |
| Control trajectory computed by line-search procedure. | |
| std::vector< Eigen::VectorXd > | Vx_ |
| Gradient of the Value function \(\mathbf{V_x}\). | |
| std::vector< Eigen::MatrixXd > | Vxx_ |
| Hessian of the Value function \(\mathbf{V_{xx}}\). | |
| Eigen::MatrixXd | Vxx_tmp_ |
| Temporary variable for ensuring symmetry of Vxx. | |
| Eigen::VectorXd | xnext_ |
| Next state \(\mathbf{x}^{'}\). | |
| std::vector< Eigen::VectorXd > | xs_try_ |
| State trajectory computed by line-search procedure. | |
| Protected Attributes inherited from SolverAbstract | |
| std::vector< boost::shared_ptr< CallbackAbstract > > | callbacks_ |
| Callback functions. | |
| double | cost_ |
| Total cost. | |
| Eigen::Vector2d | d_ |
| LQ approximation of the expected improvement. | |
| double | dV_ |
Cost reduction obtained by tryStep() | |
| double | dVexp_ |
| Expected cost reduction. | |
| double | ffeas_ |
| Feasibility of the dynamic constraints. | |
| std::vector< Eigen::VectorXd > | fs_ |
| Gaps/defects between shooting nodes. | |
| bool | inffeas_ |
| bool | is_feasible_ |
| Label that indicates is the iteration is feasible. | |
| std::size_t | iter_ |
| Number of iteration performed by the solver. | |
| boost::shared_ptr< ShootingProblem > | problem_ |
| optimal control problem | |
| double | steplength_ |
| Current applied step-length. | |
| double | stop_ |
Value computed by stoppingCriteria() | |
| double | th_acceptstep_ |
| Threshold used for accepting step. | |
| double | th_gaptol_ |
| Threshold limit to check non-zero gaps. | |
| double | th_stop_ |
| Tolerance for stopping the algorithm. | |
| double | tmp_feas_ |
| Temporal variables used for computed the feasibility. | |
| double | ureg_ |
| Current control regularization values. | |
| std::vector< Eigen::VectorXd > | us_ |
| Control trajectory. | |
| bool | was_feasible_ |
| Label that indicates in the previous iterate was feasible. | |
| double | xreg_ |
| Current state regularization value. | |
| std::vector< Eigen::VectorXd > | xs_ |
| State trajectory. | |
Differential Dynamic Programming (DDP) solver.
The DDP solver computes an optimal trajectory and control commands by iterates running backwardPass() and forwardPass(). The backward-pass updates locally the quadratic approximation of the problem and computes descent direction. If the warm-start is feasible, then it computes the gaps \(\mathbf{f}_s\) and run a modified Riccati sweep:
\begin{eqnarray*} \mathbf{Q}_{\mathbf{x}_k} &=& \mathbf{l}_{\mathbf{x}_k} + \mathbf{f}^\top_{\mathbf{x}_k} (V_{\mathbf{x}_{k+1}} + V_{\mathbf{xx}_{k+1}}\mathbf{\bar{f}}_{k+1}),\\ \mathbf{Q}_{\mathbf{u}_k} &=& \mathbf{l}_{\mathbf{u}_k} + \mathbf{f}^\top_{\mathbf{u}_k} (V_{\mathbf{x}_{k+1}} + V_{\mathbf{xx}_{k+1}}\mathbf{\bar{f}}_{k+1}),\\ \mathbf{Q}_{\mathbf{xx}_k} &=& \mathbf{l}_{\mathbf{xx}_k} + \mathbf{f}^\top_{\mathbf{x}_k} V_{\mathbf{xx}_{k+1}} \mathbf{f}_{\mathbf{x}_k},\\ \mathbf{Q}_{\mathbf{xu}_k} &=& \mathbf{l}_{\mathbf{xu}_k} + \mathbf{f}^\top_{\mathbf{x}_k} V_{\mathbf{xx}_{k+1}} \mathbf{f}_{\mathbf{u}_k},\\ \mathbf{Q}_{\mathbf{uu}_k} &=& \mathbf{l}_{\mathbf{uu}_k} + \mathbf{f}^\top_{\mathbf{u}_k} V_{\mathbf{xx}_{k+1}} \mathbf{f}_{\mathbf{u}_k}. \end{eqnarray*}
Then, the forward-pass rollouts this new policy by integrating the system dynamics along a tuple of optimized control commands \(\mathbf{u}^*_s\), i.e.
\begin{eqnarray} \mathbf{\hat{x}}_0 &=& \mathbf{\tilde{x}}_0,\\ \mathbf{\hat{u}}_k &=& \mathbf{u}_k + \alpha\mathbf{k}_k + \mathbf{K}_k(\mathbf{\hat{x}}_k-\mathbf{x}_k),\\ \mathbf{\hat{x}}_{k+1} &=& \mathbf{f}_k(\mathbf{\hat{x}}_k,\mathbf{\hat{u}}_k). \end{eqnarray}
backwardPass() and forwardPass()
|
explicit |
|
virtual |
Compute the optimal trajectory \(\mathbf{x}^*_s,\mathbf{u}^*_s\) as lists of \(T+1\) and \(T\) terms.
From an initial guess init_xs, init_us (feasible or not), iterate over computeDirection() and tryStep() until stoppingCriteria() is below threshold. It also describes the globalization strategy used during the numerical optimization.
| [in] | init_xs | initial guess for state trajectory with \(T+1\) elements (default []) |
| [in] | init_us | initial guess for control trajectory with \(T\) elements (default []) |
| [in] | maxiter | maximum allowed number of iterations (default 100) |
| [in] | is_feasible | true if the init_xs are obtained from integrating the init_us (rollout) (default false) |
| [in] | init_reg | initial guess for the regularization value. Very low values are typical used with very good guess points (default 1e-9). |
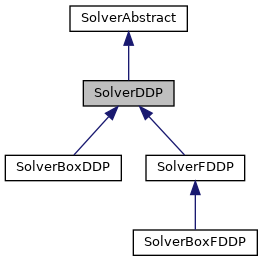
Implements SolverAbstract.
Reimplemented in SolverFDDP.
|
virtual |
Compute the search direction \((\delta\mathbf{x}^k,\delta\mathbf{u}^k)\) for the current guess \((\mathbf{x}^k_s,\mathbf{u}^k_s)\).
You must call setCandidate() first in order to define the current guess. A current guess defines a state and control trajectory \((\mathbf{x}^k_s,\mathbf{u}^k_s)\) of \(T+1\) and \(T\) elements, respectively.
| [in] | recalc | true for recalculating the derivatives at current state and control |
Implements SolverAbstract.
|
virtual |
Try a predefined step length \(\alpha\) and compute its cost improvement \(dV\).
It uses the search direction found by computeDirection() to try a determined step length \(\alpha\). Therefore, it assumes that we have run computeDirection() first. Additionally, it returns the cost improvement \(dV\) along the predefined step length \(\alpha\).
| [in] | steplength | applied step length ( \(0\leq\alpha\leq1\)) |
Implements SolverAbstract.
|
virtual |
Return a positive value that quantifies the algorithm termination.
These values typically represents the gradient norm which tell us that it's been reached the local minima. The stopping criteria strictly speaking depends on the search direction (calculated by computeDirection()) but it could also depend on the chosen step length, tested by tryStep().
Implements SolverAbstract.
|
virtual |
Return the expected improvement \(dV_{exp}\) from a given current search direction \((\delta\mathbf{x}^k,\delta\mathbf{u}^k)\).
For computing the expected improvement, you need to compute the search direction first via computeDirection().
Implements SolverAbstract.
Reimplemented in SolverFDDP.
|
virtual |
Resizing the solver data.
If the shooting problem has changed after construction, then this function resizes all the data before starting resolve the problem.
Reimplemented from SolverAbstract.
Reimplemented in SolverBoxDDP, and SolverBoxFDDP.
|
virtual |
Update the Jacobian, Hessian and feasibility of the optimal control problem.
These derivatives are computed around the guess state and control trajectory. These trajectory can be set by using setCandidate().
|
virtual |
Run the backward pass (Riccati sweep)
It assumes that the Jacobian and Hessians of the optimal control problem have been compute (i.e., calcDiff()). The backward pass handles infeasible guess through a modified Riccati sweep:
\begin{eqnarray*} \mathbf{Q}_{\mathbf{x}_k} &=& \mathbf{l}_{\mathbf{x}_k} + \mathbf{f}^\top_{\mathbf{x}_k} (V_{\mathbf{x}_{k+1}} + V_{\mathbf{xx}_{k+1}}\mathbf{\bar{f}}_{k+1}),\\ \mathbf{Q}_{\mathbf{u}_k} &=& \mathbf{l}_{\mathbf{u}_k} + \mathbf{f}^\top_{\mathbf{u}_k} (V_{\mathbf{x}_{k+1}} + V_{\mathbf{xx}_{k+1}}\mathbf{\bar{f}}_{k+1}),\\ \mathbf{Q}_{\mathbf{xx}_k} &=& \mathbf{l}_{\mathbf{xx}_k} + \mathbf{f}^\top_{\mathbf{x}_k} V_{\mathbf{xx}_{k+1}} \mathbf{f}_{\mathbf{x}_k},\\ \mathbf{Q}_{\mathbf{xu}_k} &=& \mathbf{l}_{\mathbf{xu}_k} + \mathbf{f}^\top_{\mathbf{x}_k} V_{\mathbf{xx}_{k+1}} \mathbf{f}_{\mathbf{u}_k},\\ \mathbf{Q}_{\mathbf{uu}_k} &=& \mathbf{l}_{\mathbf{uu}_k} + \mathbf{f}^\top_{\mathbf{u}_k} V_{\mathbf{xx}_{k+1}} \mathbf{f}_{\mathbf{u}_k}, \end{eqnarray*}
where \(\mathbf{l}_{\mathbf{x}_k}\), \(\mathbf{l}_{\mathbf{u}_k}\), \(\mathbf{f}_{\mathbf{x}_k}\) and \(\mathbf{f}_{\mathbf{u}_k}\) are the Jacobians of the cost function and dynamics, \(\mathbf{l}_{\mathbf{xx}_k}\), \(\mathbf{l}_{\mathbf{xu}_k}\) and \(\mathbf{l}_{\mathbf{uu}_k}\) are the Hessians of the cost function, \(V_{\mathbf{x}_{k+1}}\) and \(V_{\mathbf{xx}_{k+1}}\) defines the linear-quadratic approximation of the Value function, and \(\mathbf{\bar{f}}_{k+1}\) describes the gaps of the dynamics.
|
virtual |
Run the forward pass or rollout.
It rollouts the action model given the computed policy (feedforward terns and feedback gains) by the backwardPass():
\begin{eqnarray} \mathbf{\hat{x}}_0 &=& \mathbf{\tilde{x}}_0,\\ \mathbf{\hat{u}}_k &=& \mathbf{u}_k + \alpha\mathbf{k}_k + \mathbf{K}_k(\mathbf{\hat{x}}_k-\mathbf{x}_k),\\ \mathbf{\hat{x}}_{k+1} &=& \mathbf{f}_k(\mathbf{\hat{x}}_k,\mathbf{\hat{u}}_k). \end{eqnarray}
We can define different step lengths \(\alpha\).
| stepLength | applied step length ( \(0\leq\alpha\leq1\)) |
Reimplemented in SolverFDDP, SolverBoxDDP, and SolverBoxFDDP.
|
virtual |
Compute the feedforward and feedback terms using a Cholesky decomposition.
To compute the feedforward \(\mathbf{k}_k\) and feedback \(\mathbf{K}_k\) terms, we use a Cholesky decomposition to solve \(\mathbf{Q}_{\mathbf{uu}_k}^{-1}\) term:
\begin{eqnarray} \mathbf{k}_k &=& \mathbf{Q}_{\mathbf{uu}_k}^{-1}\mathbf{Q}_{\mathbf{u}},\\ \mathbf{K}_k &=& \mathbf{Q}_{\mathbf{uu}_k}^{-1}\mathbf{Q}_{\mathbf{ux}}. \end{eqnarray}
Note that if the Cholesky decomposition fails, then we re-start the backward pass and increase the state and control regularization values.
Reimplemented in SolverBoxDDP, and SolverBoxFDDP.
| DEPRECATED | ( | "Use get_reg_incfactor() or get_reg_decfactor()" | , |
| double get_regfactor() const ; | |||
| ) | const |
Return the regularization factor used to decrease / increase it.
Return the minimum regularization value
| DEPRECATED | ( | "Use set_reg_incfactor() or set_reg_decfactor()" | , |
| void set_regfactor(const double reg_factor); | |||
| ) | const |
Modify the regularization factor used to decrease / increase it.
Modify the minimum regularization value
 1.8.17
1.8.17